就面试总问到 HashMap,蚊子就总说的一知半解,就研究了一下(其实也没有面几家,基本都简历杀了,呜呜呜呜呜~)
~<待完成>~
继承关系
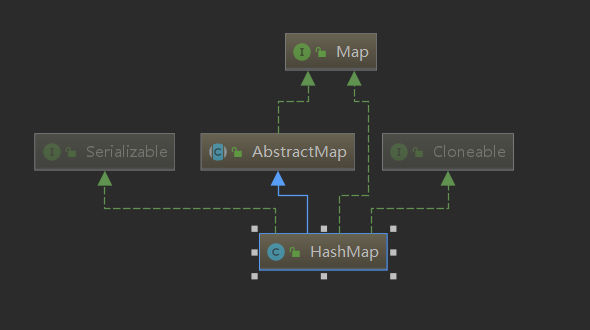
先来看一下 HashMap 的类图,如下图所示, HashMap 继承于 AbstractMap,实现了 Serialzable、Cloneable 和 Map 这三个接口。
底层参数
1 | /** |
DEFAULT_LOAD_FACTOR:负载因子,默认值为 0.75f,所谓的负载因子就是HashMap的容量达到0.75时的时候会试试扩容resize(), (例:假设有一个 HashMap 的初始容量为 16 ,那么扩容的阀值就是 0.75 * 16 = 12 。也就是说,在你打算存入第 13 个值的时候,HashMap 会先执行扩容)。负载因子也能通过构造方法中指定,如果指定大于1,则数组不会扩容,牺牲了性能不过提升了内存。
TREEIFY_THRESHOLD:树形化阈值,默认为 8,当链表的节点个数大于等于这个值时,会将链表转化为红黑树,该值必须大于等于2 且小于等于8。(为什么默认为 8,是因为红黑树中节点的频率遵循泊松分布,概率为0.5,默认大小调整阈值为0.75,虽然由于调整粒度而具有很大的差异。忽略方差,列表大小k的预期出现是 $exp(-0.5) * \frac{0.5^k}{k!}$。第一个值为:0.60653066,期望还是很大的,但是到了第八个值就为0.00000006,不到千万分之一。所以默认值为8)
UNTREEIFY_THRESHOLD:解除树形化阈值,默认为 6,要小于TREEIFY_THRESHOLD,并且在最多6个与去除时的收缩检测啮合。
MIN_TREEIFY_CAPACITY:最小的树形化容量,默认为 64,至少为 4 * TREEIFY_THRESHOLD,以避免调整数组容量大小和树化阈值之间的冲突。所以在检查链表长度转换成红黑树之前,还会先检测当前数组数组是否到达一个阈值(64),如果没有到达这个容量,会放弃转换,先去扩充数组。
数据结构
1 | // Node是单向链表节点,Entry是双向链表节点 |
构造方法
1 | /** |
1 | /** |
1 | /** |
方法解析
tableSizeFor 方法
可以看到上面的构造函数中有一个 threshold,在第一次 put 操作时,它表示为数组的初始容量。之后都会根据传入的参数 initialCapacity 重新计算这个 threshold,而计算的方法就是这个 tableSizeFor 方法。
1 | /** |
hash 方法
HashMap 采用 hash 算法来决定集合中元素的存储位置,每当系统初始化 HashMap 时,会创建一个为 capacity 的数组,这个数组里面可以存储元素的位置被成为 桶(bucket), 每个 bucket 都有其指定索引。可以根据该索引快速访问存储的元素。
1 | /** |
在Java中每个对象都会拥有一个hashCode()方法,这个就是散列函数,通过这个方法会返回一个 32 位的整数,使用这么大的值作为哈希值其实是为了尽量避免发生碰撞(相同),例如两个不同对象的 hashCode 一样的话那就是发生了碰撞。但是如果用这么长的数字来当做索引肯定是不行的,那需要数组有多大才行?所以我们需要把这个 hashCode 缩小到规定数组的长度范围内。
上面的代码只是用hashCode的 高 16 位与低 16 位进行异或运算。hash() 方法就是将 hashCode 进一步的混淆,增加其“随机度”,试图减少插入 HashMap 时的 hash 冲突。
在 putVal 方法中,有一行这样的代码
1 | if ((p = tab[i = (n - 1) & hash]) == null) |
i = (n - 1) & hash,n 是数组长度,hash 就是通过 hash() 方法进行 高低位异或运算 得出来的 hash 值。 这个表达式就是 hash 值的取模运算,上面已经说过当除数为 2 的次方时,可以用与运算提高性能。
那么为什么要这样计算,即主要解答以下3个问题:
- 为什么不直接采用经过
hashCode()处理的哈希码 作为 存储数组table的下标位置?
- 结论:容易出现 哈希码 与 数组大小范围不匹配的情况,即 计算出来的哈希码可能 不在数组大小范围内,从而导致无法匹配存储位置
- 为了解决 “哈希码与数组大小范围不匹配” 的问题,
HashMap给出了解决方案:哈希码 与运算(&) (数组长度-1),即问题3
- 为什么采用 哈希码 与运算(&) (数组长度-1) 计算数组下标?
- 结论:根据 HashMap 的容量大小(数组长度),按需取 哈希码一定数量的低位 作为存储的数组下标位置,从而 解决 “哈希码与数组大小范围不匹配” 的问题。
- 为什么在计算数组下标前,需对哈希码进行二次处理:扰动处理?
- 结论:加大哈希码低位的随机性,使得分布更均匀,从而提高对应数组存储下标位置的随机性 & 均匀性,最终减少Hash冲突。
put 方法
整个 put 过程,其实就是:
1.检查数组是否为空,是则执行 resize() 扩充;
2.通过 hash 值计算数组索引,获取该索引位的首节点。
3.如果首节点为null(没发生碰撞),直接添加节点到该索引位(bucket)。
4.如果首节点不为null(发生碰撞),那么有3种情况:
① key和首节点的key相同,覆盖old value(保证key的唯一性);否则执行②或③
② 如果首节点是红黑树节点(TreeNode),将键值对添加到红黑树。
③ 如果首节点是链表,将键值对添加到链表。添加之后会判断链表长度是否到达 TREEIFY_THRESHOLD - 1 这个阈值,达到则 “尝试” 将链表转换成红黑树。
5.最后判断当前元素个数是否大于 threshold,是则扩充数组。
1 | public V put(K key, V value) { |
上面的注释有说到,当链表达到 7 的时候,开始 “尝试” 将链表转化为红黑树,是因为红黑树的平均查找长度是 log(n),长度为 8,查找长度为 log(8) = 3,链表的平均查找长度为 n/2,当长度为 8 时,平均查找长度为 8/2 = 4,这才有转换成树的必要;链表长度如果是小于等于 6,6/2 = 3,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。
以 6 和 8 来作为平衡点是因为,中间有个差值 7 可以防止链表和树之间频繁的转换。假设,如果设计成链表个数超过8则链表转换成树结构,链表个数小于 8 则树结构转换成链表,如果一个 HashMap 不停的插入、删除元素,链表个数在 8 左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
概括起来就是:链表:如果元素小于8个,查询成本高,新增成本低,红黑树:如果元素大于8个,查询成本低,新增成本高。
resize 方法
对于 resize 的过程,分为几步:
1.根据原本的表,来判断数组是否被初始化,是则根据所调用的构造函数进行初始化。
2.计算新阈值(为旧阈值的两倍),生成新数组,将旧数组的所有元素移到新数组上去。
3.计算索引,这里分为三种情况:
① 如果链表只有一个节点,那么直接重新计算索引存入新数组。
② 如果是红黑树,则进行单独处理。
③ 如果是链表,则根据原来的 hash 值新增的那个 bit 是 1 还是 0 来建立两个链表,是 0 的话就存入原本的链表(索引没变),是 1 的话就存入新建立的链表上面(索引变成“原索引+oldCap”)。
1 | /** |
get 方法
对于 get 方法,分为以下几个步骤:
1.检查数组是否为 null 和 索引位首节点(bucket的第一个节点)是否为 null。
2.如果索引节点的 hash == key 的 hash 或者 key 和索引节点的 k 相同则直接返回(bucket的第一个节点)。
3.如果是红黑色则到红黑树查找。
4.如果有冲突,则通过 key.equals(k) 查找。
5.都没找到就返回null。
1 | public V get(Object key) { |
并发问题
HashMap 在多线程 put 后可能导致 get 无限循环
JDK8 之前,是插入数据的方式是采用的头插法来进行数据的插入,在并发put下可能造成死循环。原因是多线程下单链表的数据结构被破环,指向混乱,造成了链表成环。JDK8 中插入数据的方式是采用的尾插法,避免了这一问题的发生。
多线程 put 的时候可能导致元素丢失
如果两个线程同时读取到当前 node,在链表尾部插入,先插入的线程是无效的,会被后面的线程覆盖掉。
1.7 和 1.8 的区别
引入红黑树
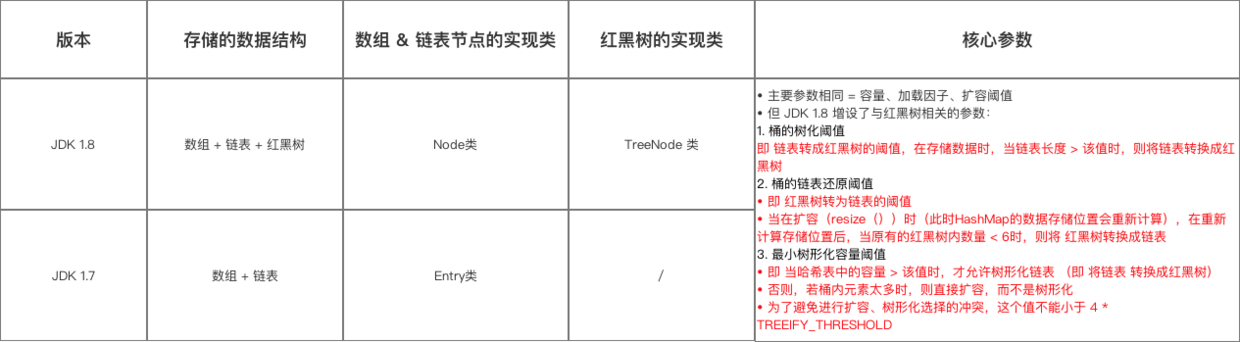
在 jdk 1.8 中,优化了 HashMap 的数据结构:引入了红黑树,即 HashMap 的数据结构 = 数组 + 链表 + 红黑树,而 jdk 1.7 中 HashMap 的数据结构 = 数组 + 链表
引入原因:
提高了 HashMap 的性能,即解决了发生过 哈希碰撞后,链表过长从而导致索引效率慢的问题。
应用场景:
当链表长度 > 8 时,将该链表转换为红黑树,即红黑树作为存储结构 & 解决 Hash 冲突的第 3 方案
(ps:1.无冲突时:存放在数组里;2.冲突 & 链表长度 < 8 时:存放在单链表里;3.冲突 & 链表长度 > 8 时:存放在红黑树里)
hash 方法的实现
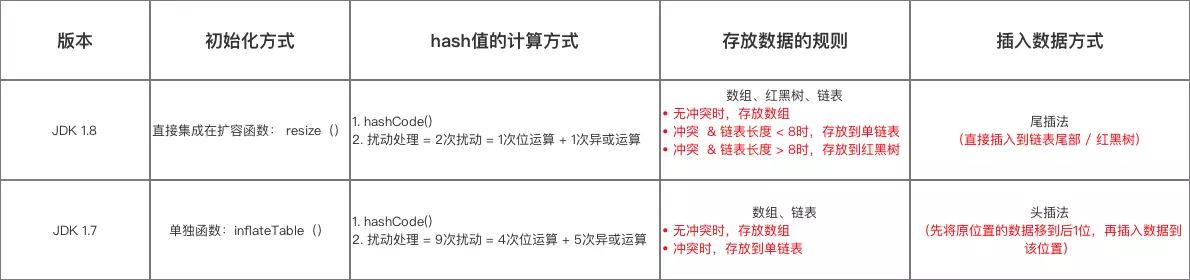
对于 jdk 1.8 和 jdk 1.7 两者来说,hash() 方法都使用了扰动函数来计算传入数据的 hashcode,不过它们两者的实现略有不同:
jdk 1.7 做了9次扰动处理 = 4次位运算 + 5次异或运算
jdk 1.8 简化了扰动函数 = 只做了2次扰动 = 1次位运算 + 1次异或运算
1 | // JDK 1.7实现:将 键key 转换成 哈希码(hash值)操作 = 使用hashCode() + 4次位运算 + 5次异或运算(9次扰动) |
resize 扩容
1.异常情况判断:jdk 1.8 有对扩容异常情况判断,即是否需初始化、当前容量是否 > 最大值;jdk 1.7 则没有
2.重新计算每个数据在新数组中的存储位置:jdk 1.8 是通过新增的bit判断索引位;jdk 1.7 是通过重新计算每个元素的索引,重新存入新的数组,称为rehash操作。
3.转移数据方式:jdk 1.8 是采用尾插法,直接插入链表尾部 / 红黑树,不会出现逆序 & 环形链表死循环问题;jdk 1.7 是采用头插法,先将原位置的数据移到后 1 位,再插入数据到该位置,会出现逆序 & 环形链表死循环问题。
